


News
Insights
In-depth analysis from our expert teams
Latest

Insight
Software Leadership Gathering 2025: Accelerated Intelligence

Orbit Podcast
AI, Control Points, and the Next Wave of Vertical SaaS with Tidemark Capital founder, Dave Yuan

Insight
"In a world of software abundance, all that matters is taste"...
Insight
The AI Development Revolution

Orbit Podcast
Refounding in the face of AI with Des Traynor of Intercom

Insight
Redesigning the Customer Journey with an AI-first Mindset
Insight
Securing the Future: AI-powered cybersecurity strategies

News
Hg strengthens executive team with promotions and CIO appointment

Orbit Podcast
A golden age of software engineering with Russell Kaplan of Cognition

News
IFS valued at €15 billion in minority stake sale

News
Hg private wealth offering surpasses $1 billion

News
smartTrade Announces Strategic Investment from TA alongside CEO and Management

News
P&I secures further backing from Hg in €5.5 billion transaction

Orbit Podcast
Quick and dirty prototypes with Andrew Ng

News
Scopevisio partners with Hg to accelerate growth in DACH region
Insight
Hg's Silicon Valley Leadership Summit

Insight
Tara Anand Carter on the Innovators' Exchange podcast

News
Trackunit Announces Investment from Goldman Sachs Alternatives

Insight
Taking a triangulated approach to monetising GenAI
Orbit Podcast
A glimpse of the next generation: Zoe Zhao and Annalise Dragic of Azlin Software

Insight
Customer experience: from cost-center to revenue generator

Insight
Alan Cline's 2025 Outlook with PE Hub

News
Hg tops AGC's total deal counts ranking for 2024

News
Citation welcomes new investment from HarbourVest Partners

Insight
Septeo: La Success Story

News
Florian Brokamp establishes new consortium for insurance brokers

Orbit Podcast
Incubate, experiment and implement: the real business case for AI today

News
IRIS Software Group Announces Intent to Acquire Dext Software Ltd.

Orbit Podcast
Risk-taking & resilience with Sukhinder Singh-Cassidy, CEO of Xero

News
Septeo Group welcomes new investors Téthys Invest and GIC
News
Empyrean Solutions Secures Significant Investment from Hg

Insight
GenAI: the land of the bold & brave

Orbit Podcast
Vulnerability as strength in business: Nick Mehta of Gainsight

Orbit Podcast
Thousands of small experiments: Merete Hverven of Visma

Orbit Podcast
The art of pattern recognition: Darren Roos of IFS

Insight
Auditboard and Hg featured in Business Insider
News
Ncontracts acquires Venminder via Hg buyout

Orbit Podcast
Do tech leaders have to be tech experts?: Elona Mortimer-Zhika of IRIS

Insight
The Power of Unity: how European insurance brokers can harness technology and thrive

Insight
Alan Cline speaks at GrowthCap Forum

Orbit Podcast
The business case for AI: Brent Hayward of Salesforce, David Carmona of Microsoft & Nagraj Kashyap of Touring Capital

Insight
Benedikt Joeris discusses GGW Group with Finance Magazin
News
CTAIMA and e-coordina join forces

News
Sofina invests in team.blue

Orbit Podcast
The greatest tech comes when we ignore ROI: Raghu Raghuram of VMware

Insight
Navigating risks to reap the rewards of AI
News
team.blue welcomes new investment from CPP

News
Hg joins the CyberFirst programme

Orbit Podcast
Mastering the billion-dollar software playbook: Joe Lonsdale of 8VC & Eric Poirier of Addepar

News
F24 to accelerate growth with new investment from Altor

Insight
Software Leadership Gathering 2024: Shifting Techtonics

News
Matthew Brockman joins Daybreak Europe at Bloomberg

Insight
Electricity in the air: a journey to the frontier of GenAI
News
AuditBoard agrees to be acquired by Hg for over $3 billion

Insight
We're only laying the foundations: a Digital Summit Conversation

News
CUBE acquires global regulatory intelligence businesses from Thomson Reuters

News
CUBE acquires Reg-Room
News
Hg strengthens executive team with six senior appointments
News
Hg completes its investment into GGW

Insight
Inspiration to Innovation: Ensuring success of AI in your product

News
Focus Group secures new investment from Hg

Insight
David and David review David’s NRR analysis. What’s the recurrent theme?

Insight
40 years of Gen AI at Hg

Insight
The AI Squared Enterprise: AI, Automation, Integration
News
CUBE and Hg unite to create regulatory compliance and risk platform

Insight
Hg’s Steven Batchelor: You can be IRR and MOIC driven

Insight
Gen AI will revolutionize software. Now what?

News
Induver and Clover join forces alongside Hg

Insight
Alan Cline speaks on Growth Investor

Insight
Recruiting for potential: Tim Barker speaks to Ideagen COO, James King

Insight
Hg and Visma featured in the Financial Times

News
Argus announces strategic transaction to support next phase of growth

Insight
Nic Humphries discusses Visma on Business Breakdowns

Insight
Alan Cline: 'The AI revolution is real'

News
Hg closes sale of MeinAuto Group divisions to the Renault Group

News
IRIS Software Group secures major US investment from Leonard Green & Partners

News
Visma attracts new investors for further international expansion in a transaction valuing the company at EUR 19 billion

News
Hg tops AGC Partner's list for tech deals done in 2023

News
CINC Systems secures meaningful strategic investment from Hg

News
GGW Group secures investment from Permira as the firm scales as a leading insurance brokerage group in Europe

Orbit Podcast
What drives business quality in an era of AI and digital platforms?: Jonathan Knee of Evercore

News
Hg launches Fusion
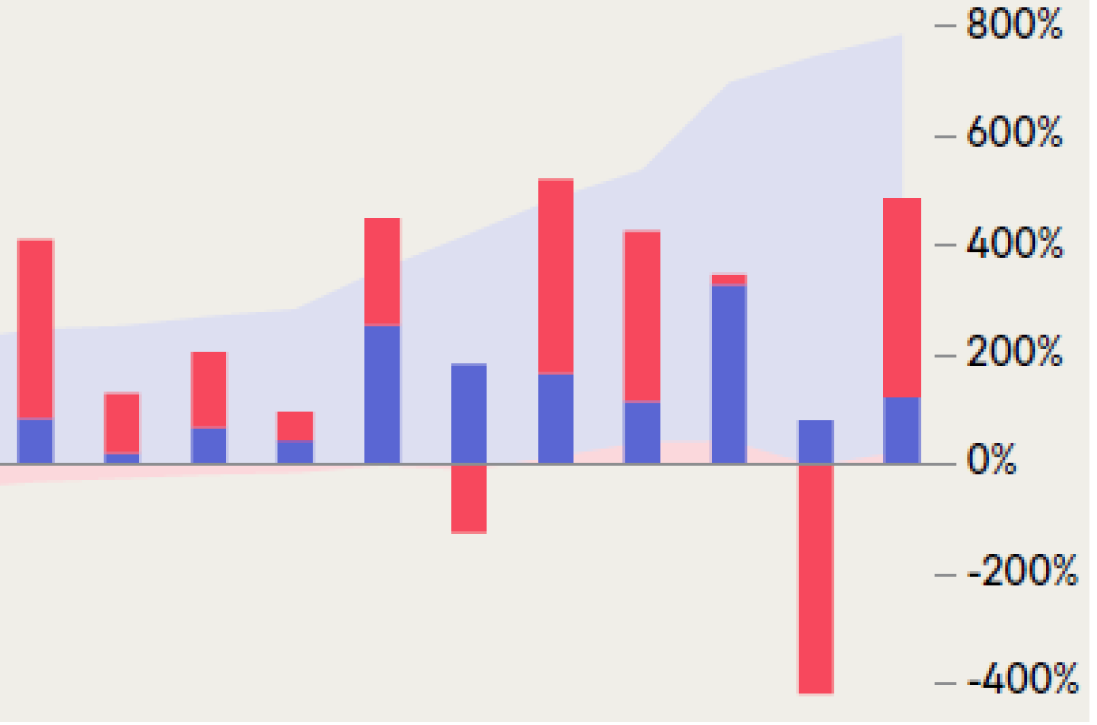
Insight
Earnings growth wins every time

News
JTL secures investment from Hg to fund further growth as a European champion in e-commerce software

Orbit Podcast
Pace of innovation

Orbit Podcast
Harnessing a new superpower

Orbit Podcast
LLM AI, the fourth pillar of software

News
Visma strengthens position as Europe’s cloud accounting champion with acquisition of Silverfin

Orbit Podcast
Life as a service

News
Farouk Hussein joins Hg in North America

News
ECI Partners invests in Commify, Europe's leading provider of business messaging solutions to Local Enterprises

News
Nomadia secures investment from Hg

News
Paul Zuber joins Hg in North America

Orbit Podcast
Insuring the insurers

Orbit Podcast
Future ancestors

News
Azets Group secures investment from PAI Partners to join Hg and support next phase of growth

News
Staying ahead: AI takeaways from Hg's Senior Leadership Gathering 2023

News
Hg goes top 10 in the PEI300

Orbit Podcast
The modern data stack

News
GTreasury secures investment from Hg to accelerate growth as a global Treasury Management Software platform
Insight
Striking the balance: the tradeoff between growth and margin

News
Built to last: why a narrow focus is the secret to Hg’s success

News
A fresh look for Hg

News
Hg to build out dedicated wealth team

Orbit Podcast
What does AI mean to you?

News
Alan Cline joins Hg as Head of North America
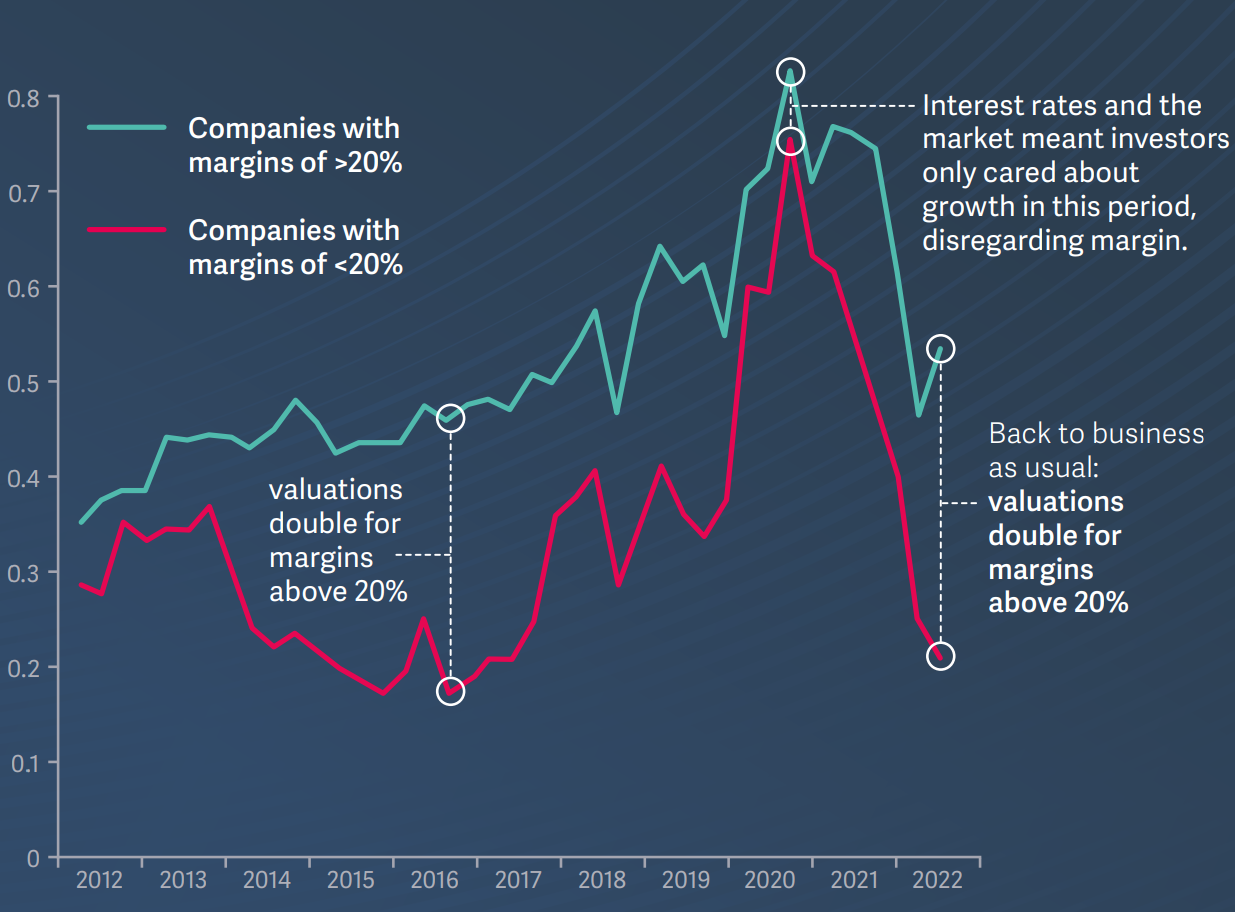
Insight
Cooler heads continue to prevail

News
AGC Partners ranks Hg as #1 most active tech investor

Orbit Podcast
Investors in Enduring Growth
News
Hg agrees to sale of Transporeon for €1.88 billion
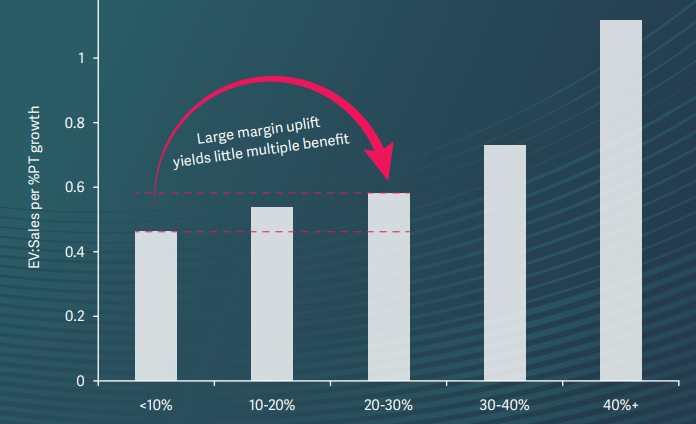
Insight
The trade-off between growth and margin

Orbit Podcast
Poacher turned gatekeeper

Insight
A Love Letter to ESRI

Orbit Podcast
The Pace of Automation

News
Ideagen and ProcessMAP to combine their strengths to create a world-leading health and safety software solution

News
TrustQuay secures Hg investment to further accelerate its vision to digitalise the Trust, Corporate and Fund Service sector
Orbit Podcast
Insurance, the O.G. Data Business

Insight
Legaltech Cloudspotting

Orbit Podcast
Building a Growth Engine

Orbit Podcast
Unravelling the Orthodoxy

News
Cornerstone VC reaches first close of £20m fund to back UK tech start-ups led by diverse teams

Orbit Podcast
To be of Value

News
Intelerad announces significant investment from TA to accelerate growth

Orbit Podcast
Sustainable IT and IT for Sustainability

News
Ideagen secures partnership with Hg to support further growth as a regulatory and compliance software leader

News
team.blue strengthens leadership team and prepares for further expansion
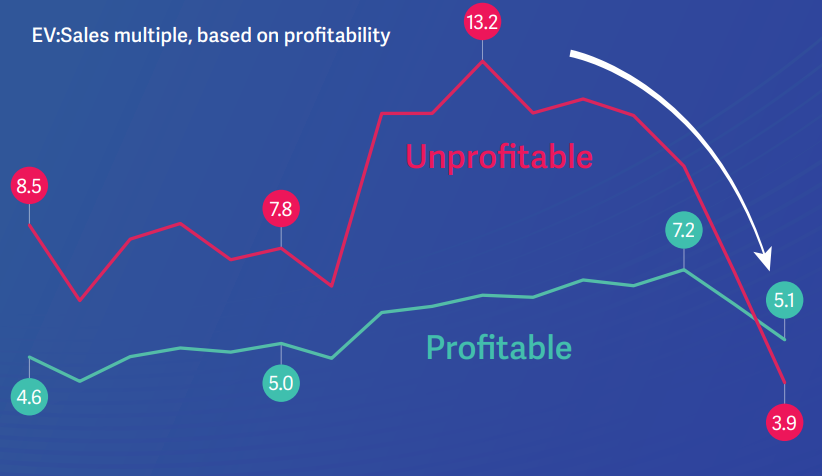
News
The profitable vs. unprofitable trend continues

News
Norstella announces agreement to merge with Citeline

Orbit Podcast
Unlocking real-time behavioral data in SaaS

News
Hg agrees sale of MEDIFOX DAN to ResMed for US$1bn

News
Howden Group creates new $30bn force in global broking through landmark TigerRisk deal

News
The Access Group announces substantial investment to drive continued expansion at £9.2 billion valuation

News
Hg agrees the sale of itm8 to Axcel

News
The Hg Foundation appoints James Turner as its first CEO to scale its charitable activities within education and technology across the UK, Europe and U
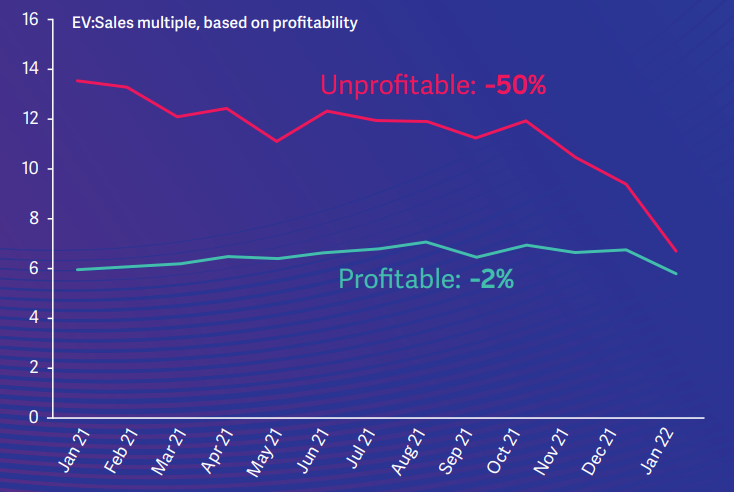
Insight
Tech meltdown? David Toms Chart of the month

News
The Hg Foundation backs Merit America to help low-wage workers access careers in tech

Orbit Podcast
Why Tech is Deflationary in an Inflationary World

News
Hg strengthens executive team

News
LucaNet AG partners with Hg to build a global leader in Corporate Performance Management

News
Hg invests in IFS and WorkWave

News
Ukraine – an update from Hg

Orbit Podcast
The Feedback Loop - Part 2

Orbit Podcast
The Death of Email? - Part 1

Orbit Podcast
The Digital Construction Site

News
The Hg Foundation forms a €750,000 partnership with The Technical University of Munich

Orbit Podcast
Never a better time than now

News
Hg Joins Private Equity Industry’s First-Ever ESG Data Convergence Project Alongside Milestone Commitment of Over 100 LPs and GPs

News
Waystone completes investment from Montagu and announces new strategic investment from Hg

Orbit Podcast
The Future of SaaS - Part 2

News
ProcessMAP partners with Hg

News
AGC Partners ranks Hg as #1 most active tech acquirer

News
Pirum Systems secures new investor to accelerate its global growth strategy

News
Fonds Finanz secures investment from Hg
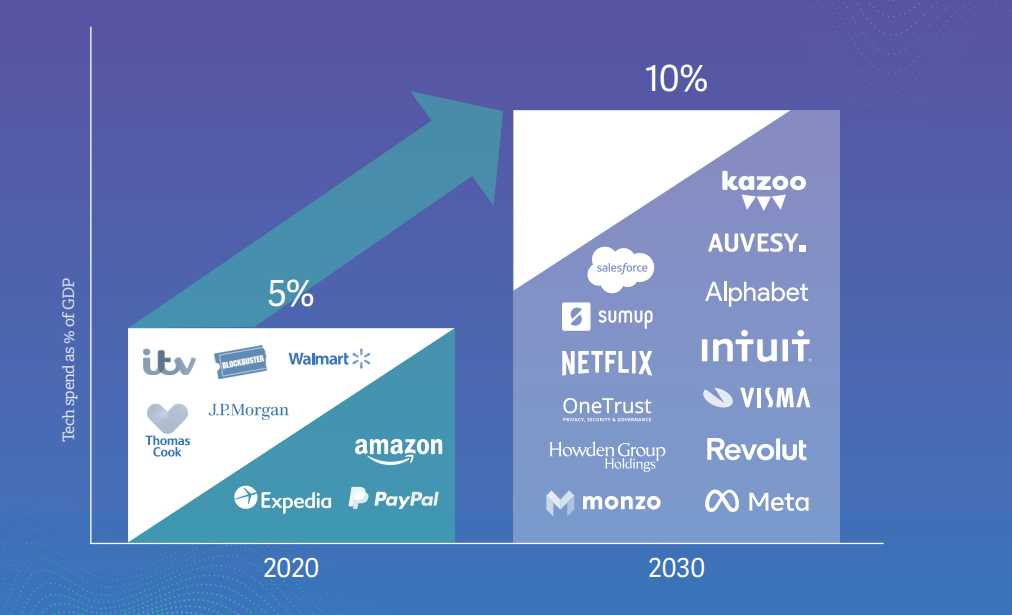
Insight
Tech spend is forecast to double Insight over the next decade, but how?

News
Revalize secures significant minority investment from Hg

Orbit Podcast
The Future of SaaS - Part 1

News
Hg in group of seven pioneering firms representing €133bn AUM to combat climate change by setting ambitious science-based targets

News
Litera secures further investment from Hg

News
Hg joins leading investors committing to net zero

Orbit Podcast
Data Science in Drug Development

Orbit Podcast
You are only as strong as your weakest point

News
Hg signs $5bn+ in Healthcare Technology

News
Leading global software investor offers STEM scholarships in Salford

News
Generation France and The Hg Foundation announce €1m+ new tech-focused partnership

Orbit Podcast
The Art of Cross-sell

Orbit Podcast
“I choose me”

Orbit Podcast
Purpose vs Profit

News
BrightPay and Relate Software join forces to create an accounting & payroll software champion

News
Trackunit and ZTR come together to connect construction

News
HHAeXchange and healthcare investor Cressey & Company welcome strategic investment from software investor, Hg, to accelerate continued growth as the leading homecare management solution provider

News
Visma attracts new Nordic and international investors as part of a strategic expansion of the shareholder base, valuing the business at €16 billion
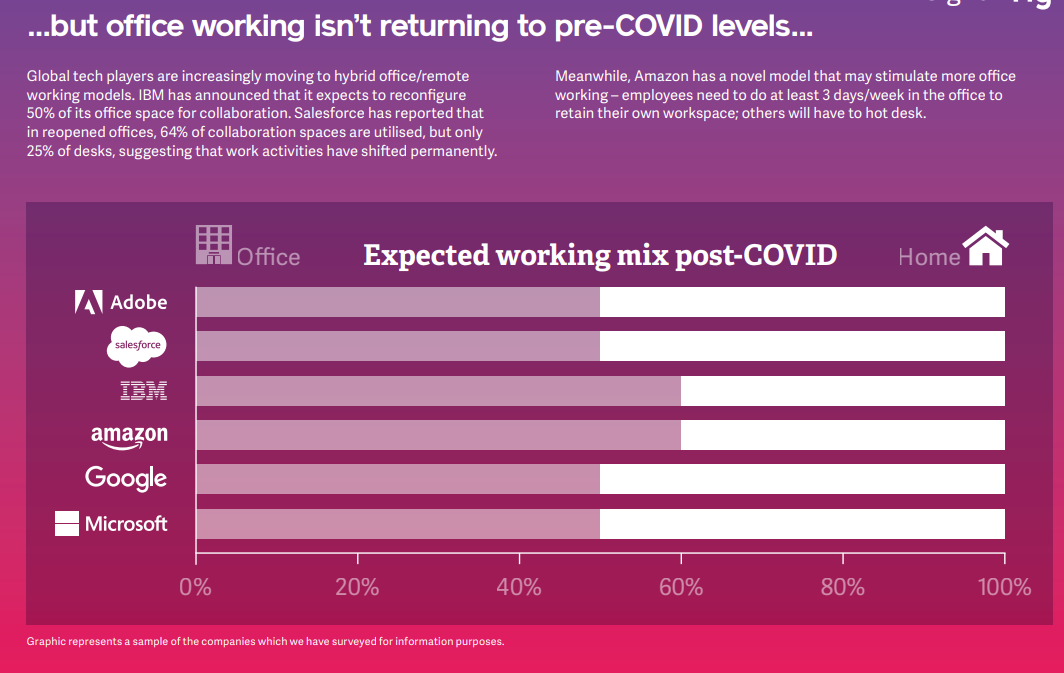
Insight
Back to the office?

News
Riskalyze Recapitalised by Hg

News
Serrala secures strategic investment from Hg

News
MMIT and Evaluate Join Forces to Offer an End-to-End View of the Pharmaceutical Market Landscape

News
Hg invests in MDT

Orbit Podcast
Respond, React & Adapt
News
insightsoftware attracts c.$1bn strategic investment from Hg

Orbit Podcast
Born in the Cloud

News
Hg agrees the sale of Allocate to RLDatix

Orbit Podcast
Volcano Cat Bonds and Other Innovations

Orbit Podcast
The Scandinavian Question

Orbit Podcast
Navigating Change in US Tech
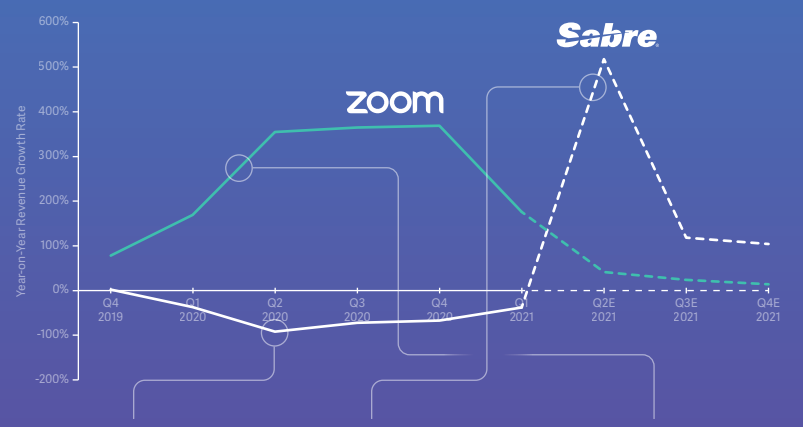
Insight
A relatively absolute Insight performance…

News
upReach and The Hg Foundation announce major new partnership
News
Hg invests in AUVESY to support the business’ leading position in the growing industrial automation sector

News
Mitratech Announces Strategic Investment from Ontario Teachers’

News
Trackunit attracts strategic investment from Hg to further accelerate the company’s journey to eliminate downtime in construction

News
Visma: one of Europe’s most inclusive companies

News
Hg sells Trace One to Symphony Technology Group

Insight
What happened to the "Rule of 40"?

News
Bloomberg TV interviews Nic Humphries and Matthew Brockman

News
Two World-Leading Impact and Sustainability Funds Invest in Benevity, Accelerating the Movement to Drive Corporate Purpose
News
The Hg Foundation partners with SEO Tech Developer

News
Hg invests in Prophix to continue to scale the business and invest further in product and technology

News
Hg invests in Geomatikk Group
News
Benevity announces investment from Hg to continue to strengthen corporate purpose globally

News
Hg invests in The Septeo Group to help continue building a leading LegalTech platform across Europe

News
Hg agrees the sale of Eucon to VHV Group

News
Gen II gains significant new investment from Global Investors to fuel continued long-term expansion

News
Hg agrees the sale of STP to Bregal Unternehmerkapital

News
CaseWare announces strategic investment from Hg

News
The Access Group reports growth and substantial investment for expansion

News
Hg invests in Hyperion in a transaction valued at $5 billion

News
Hg announces the sale of A-Plan Group

News
Hg announces new investment in The Citation Group

News
Hg leads further majority investment in Visma valued at US$12.2 billion in the world’s largest ever software buyout

News
Sovos to gain new investment

News
Hg announces KKR investment in The Citation Group

News
The launch of The Hg Foundation

News
Private: Hg in the USA

News
Committing to action on climate change with iCI

News
Hg invests in F24

News
Silverfin announces investment led by Hg to accelerate international growth

News
COVID-19 update: Resources and information from across the Hg portfolio

News
Hg strengthens executive team with four Partner promotions

News
Hg invests in smartTrade Technologies

News
MediFox and DAN Produkte merge to create MediFox DAN Group
News
Hg invests in Intelerad Medical Systems

News
IRIS: Inside one of the UK’s most prolific business software providers

News
Hg Saturn Fund acquires cloud-based HR software provider P&I from Permira funds

News
A Year in Review

News
Hg Carbon Footprint Report 2020/21

News
Litera Microsystems Acquires Workshare

News
Register Group joins team.blue

News
IRIS Software Group enters definitive agreement to acquire FMP Global
News
Rhapsody and Corepoint merge to advance Interoperability in Healthcare

News
Hg invests in TransIP to join forces with Combell

News
Hg invests in Litera Microsystems

News
Hg purchases Cinven stake in Visma

News
Hg further strengthens global executive team and opens office in New York

News
Hg Invests in Transporeon Group
News
Hg agrees the sale of Foundry
News
Hg succeeds Waterland as investor in Combell Group
News
Megabuyte50 Awards honour Commify, Foundry, Access Group, IRIS, FE & Allocate Software
News
Hg announces final closing of Hg Saturn 1 Fund at £1.5bn
News
Hg announces an investment in BrightPay
News
Hg announces investment into Allocate Software from Hg8 Fund
News
Syneos Health™ acquires Kinapse
News
Hg Invests in Orion Health Rhapsody and Population Health Businesses
News
Hg invests in IT Relation
News
Hg agrees sale of Intelliflo to Invesco
News
Visma Group intends to acquire Raet
News
Hg Saturn Fund makes new joint partnership investment in IRIS with ICG
News
Hg agrees sale of JLA to Cinven
News
Hg makes strategic investment in FE
News
Hg invests in MediFox
News
Hg agrees sale of Teufel to Naxicap Partners
News
Hg agrees sale of Radius to Vistra
News
Hg agrees sale of Allocate Software to Vista Equity Partners
News
The Access Group announces strategic investment from Hg
News
Hg announces acquisition of Mobility Concept
News
Hg investment in DADA S.p.A
News
Hg invests for the future by strengthening executive team
News
Hg announces investment in MeinAuto.de
News
Hg receives definitive binding offer from Itiviti to acquire Ullink
News
Megabuyte50 Awards honour Foundry, IRIS and Esendex
News
Hg agrees sale of Sequel to Verisk Analytics
News
Hg leads $5.3bn buyout of Visma
News
Hg announces an investment in Esendex
News
Hg sells Zitcom Group to Intelligent
News
Hg announces sale of Parts Alliance to Uni-Select
News
HgCapital announces sale of QUNDIS to KALORIMETA
News
Hg announces an investment in Mitratech
News
Hg builds for the future by strengthening executive team
News
HgCapital announces the final closing of HgCapital 8 and Mercury 2
News
HgCapital announces sale of Zenith to Bridgepoint
News
IRIS Software Group acquires PS Financials
News
HgCapital Mercury announces a significant investment in fundinfo AG
News
HgCapital announces investment in Evaluate
News
CogitalGroup which is backed by HgCapital announces an investment in Baldwins and the launch of the new Group
News
HgCapital announces investment in STP Group
News
HgCapital returns 36% IRR from the sale of Personal & Informatik to Permira funds
News
HgCapital announces an investment in Visma BPO
News
HgCapital further strengthens the executive team
News
Launch of CogitalGroup, a new advisory services business
News
HgCapital’s Mercury Fund sells Relay Software to Applied Systems
News
HgCapital agrees to sell SFC KOENIG to IDEX
News
HgCapital builds for the future by strengthening executive team
News
HgCapital announces investment in Raet
News
HgCapital announces investment in Trace One
News
HgCapital announces investment in Citation
News
HgCapital announces investment in Kinapse
News
HgCapital announces investment in Sovos Compliance
News
HgCapital announces investments in Zitcom and ScanNet
News
Hellman & Friedman acquires controlling interest in TeamSystem
News
EidosMedia receives new investment from HgCapital
News
HgCapital agrees sale of SimonsVoss to Allegion
News
HgCapital invests in The Foundry
News
HgCapital announces investment in Eucon
News
HgCapital-backed software champions shine at the inaugural megabuyte50 awards
News
The Parts Alliance recognised in international M&A awards
News
Equistone sells A-Plan Insurance to HgCapital
News
e-conomic joins forces with Sweden’s SpeedLedger
News
e-conomic and CE Consulting create a new force in Spanish accounting software
News
Parts Alliance acquires Unipart Automotive branches and jobs
News
HgCapital announces investment in Sequel Business Solutions
News
HgCapital announces investment in Relay Software
News
HgCapital announces fifteen internal promotions
News
Visma, valued at NOK 21 billion, widens shareholder base
News
Nair & Co. and High Street Partners merge to create Radius
News
HgCapital announces acquisition of Ullink
News
Successful pricing of Manx Telecom plc IPO
News
HgCapital agrees investment in Zenith
News
HgCapital completes maiden investment from Fund 7 with acquisition of Personal & Informatik AG
News
HgCapital announces sale of Epyx
News
HgCapital acquires e-conomic, Europe’s leading SaaS business for SME’s
News
HgCapital acquires Nair & Co.
News
HgCapital announces substantial investment in Intelliflo
News
HgCapital announces sale of ATC
News
HgCapital announces sale of CSH
News
HgCapital announces substantial investment in Valueworks
News
HgCapital announces the sale of SHL
News
HgCapital announces investment in QUNDIS Group
News
Kai Romberg is promoted to Partner
News
Another senior appointment to the Services team
News
Nic Humphries appears on FT.com’s Deals & Dealmakers
News
HgCapital expands its Services team
News
HgCapital is UK PE Firm of the Year
News
HgCapital announces the intended sale of Mondo Minerals
News
HgCapital announces the sale of SLV Group
News
HgCapital announces the sale of SiTel
News
News HgCapital and ATC Group announce investment
News